I accidentally built the best model!
What's data leak and how to avoid them.

Hi there!
I'm a machine learning, python guy. Reach out to me for collaboration and stuff! :D
Introduction
While back I was doing some classification on news data. It was a fake news classification problem. For this, I typed in a fake news dataset in Kaggle and a lot of datasets popped up. One of the datasets was from ISOT (Information Security and Object Technology) Research Lab. Without thinking much, I started to experiment with some traditional machine-learning algorithms, LSTMs, and transformers. To my surprise, I was getting overly optimistic results on the random forest classifier using the TD-IDF vectorization technique. Without much deliberation, I wanted to see results using some deep learning techniques. The results were similar. I checked my code for any fallacies, but it was alright. I knew that there was something wrong going on. I was getting >90% accuracy on this dataset without any problems.
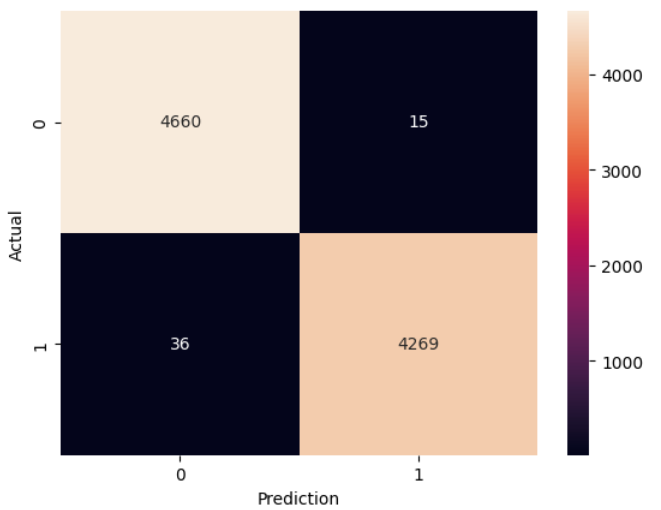
So what's wrong?
The first mistake I did was to trust the source of the data a bit too much. The source of data was a research lab at the University of Victoria and I did not think I would need to perform much EDA. And my second mistake was that I started building the model without doing any initial analysis of the dataset.
So it turns out that all the news in the true.csv file had one keyword in common. The true news was collected from a website called Reuters.com and in all of the news '(Reuters)' keyword would repeat at the beginning. To a machine learning model, it would look as if the news was from Reuters.com, it would be true and wouldn't care about what the whole news was about. I had created a biased news classifier!
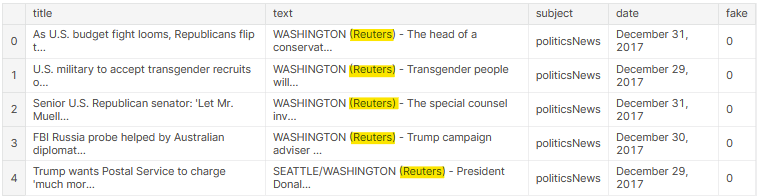
Data leakage
The technical term for this is not a 'mistake'. It's called data leakage. Data leakage occurs when you have some extra information in your training data (Like that extra keyword in the true news). You can suspect that you have a data leakage if you find yourself with overly optimistic results. The trained models will perform significantly worse in real-world applications as the model is not trained to capture various patterns. In this case, the model most probably has learned that only the news from Reuters.com is true. This will cause true news from other sources to be marked as false!
Avoiding data leaks
As I have already mentioned, do a preliminary Exploratory Data Analysis on all of your data. If I had just created a Word cloud for both of these datasets, I would have immediately spotted the problem. Make sure that the datasets used for training and testing data do not have the same data. If you have the same data for both training and testing, you would probably have higher than actual accuracy because the model has learned from test data as well. This can be easier depending on the type of data you have. For instance, you can just remove duplicated news from testing datasets in this particular problem. But let's say you are building a model to detect broken bones in X-ray images. A person without much background in biomedical will probably not be able to tell whether a data leakage is happening.
Detecting and avoiding data leakages can be a simple data engineering problem as well as may require domain experts. So, whenever you are building machine learning applications, keep this in mind.