Should I start using PyTorch Lightning?
How and why I switched from PyTorch to PyTorch Lightning.

Hi there!
I'm a machine learning, python guy. Reach out to me for collaboration and stuff! :D
I started using PyTorch only after I began my graduate studies. I had not delved into PyTorch as I was working mostly with TensorFlow and Keras when I was working in a company. The first thing I noticed switching from Keras to PyTorch was that there were some boilerplate codes that I had to write every time. Do I really need to write the whole training loop every time? Things were simple in Keras. You could just call model.fit and the whole thing would just start training. Raw PyTorch at the beginning was just figuring out why I need to write loops and call .to(device) on every object. Trust me, I spent a lot of time debugging where I forgot to call this method!
What better way to start learning new frameworks than to start building projects without referring to the documentation? That was a joke. Please refer to the official documentation. You can refer to it here. But I will show you a different example of training a CNN model in this blog. This code is inspired by PyTorch's official documentation too! I know a lot of us like to avoid documentation and refer to the blogs like this one to learn about frameworks (wink! wink!!). Keep in mind that this blog's purpose is not to teach lightening, it's to introduce lightening to you folks and talk about some pros and cons of using this.
Pytorch
Before we dive into lightning, let's see how we can train a simple CNN network using PyTorch.
import torch
import torchvision
import torchvision.transforms as transforms
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
Loading dataset.
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 4
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Defining model class.
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
net=net.to(device)
Configuring model.
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Training loop.
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
print('Finished Training')
Validation Loop.
correct = 0
total = 0
net.eval()
# since we're not training, we don't need to calculate the gradients for our outputs
with torch.no_grad():
for data in testloader:
images, labels = data
images = images.to(device)
labels = labels.to(device)
# calculate outputs by running images through the network
outputs = net(images)
# the class with the highest energy is what we choose as prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct // total} %')
As you can see, the training and validation loop look almost similar and has some boilerplate codes that I was talking about. Initially, when I saw these training loops, I felt a bit intimidated and I felt really hesitant moving from Keras to PyTorch. It made no sense to me why I was required to do net.train() to start training and net.eval() for evaluation. Do I really need to write optimizer.step() and loss.backward() for all the training loops that I write? Isn't that suppose to happen anyway? I just wanted to build a classification model. What are these codes even? Why doesn't PyTorch use GPU when it's available? Why do I have to tell it manually to use GPU? Why my code is full of bugs even when I copied it exactly from a blog? These were some questions that I had when I first started PyTorch. While these questions tormented me, it took a while to get used to them. It did give me a lot of flexibility. But do I really need this much flexibility?
Lightning
Well, for most of my work and for most of the work anyone is doing this is simply not required. I tried to reduce the boilerplate codes with my custom wrapper codes, but it did not scale and generalize well. I needed something else. At this point, I started to look for alternatives. That is when I stumbled into PyTorch Lightning and started admiring its simplicity.
The good news is that we do not have to do a lot of refactoring. The refactoring is itself removing a lot of codes from our original PyTorch code. If you intend to use Lightning in colab notebook, you have to install it using pip. We can still reuse the same dataloaders. The change starts with rewriting the code for the model. It's simple and almost the same.
from torch import nn
from torch import optim
import torch.nn.functional as F
class LitCNN(pl.LightningModule):
def __init__(self, ):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def training_step(self, batch, batch_idx):
x, y = batch
outputs = self(x)
loss = nn.CrossEntropyLoss()( outputs ,y)
# Logging to TensorBoard (if installed) by default
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
outputs = self(x)
loss = nn.CrossEntropyLoss()(outputs ,y)
# Logging to TensorBoard (if installed) by default
self.log("val_loss", loss)
return loss
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=1e-3)
return optimizer
The key difference in this class is the addition of training_step, validation_step, and configure_optimizers methods. This is a more readable and reusable approach than writing the training and validation loops in vanilla PyTorch. It will make our training process very simple. We will find out how easy it is in the next steps.
model_lite = LitCNN()
trainer = pl.Trainer(limit_train_batches=1000, limit_val_batches=500, max_epochs=2,)
trainer.fit(model=model_lite, train_dataloaders=trainloader, val_dataloaders=testloader)
We need to create an Trainer object. This trainer object adds a ton of features during training from specifying the number of epochs, to adding callbacks, loggers, and profilers. The lightning framework also has a built-in logger that uses CSV files for logging metrics by default during training and validation. Additionally, it also handles training on multiple GPUs. It supports seamless integrations with popular logging frameworks like tensorboard, MLFlow, Neptune, and Weights and Biases. Lightning also makes it very easy to train models on HPC clusters. The nettlesome to.device is no longer required as you can specify which accelerator to use in this trainer class.
As soon as you start the training process, it outputs very useful information on the console:
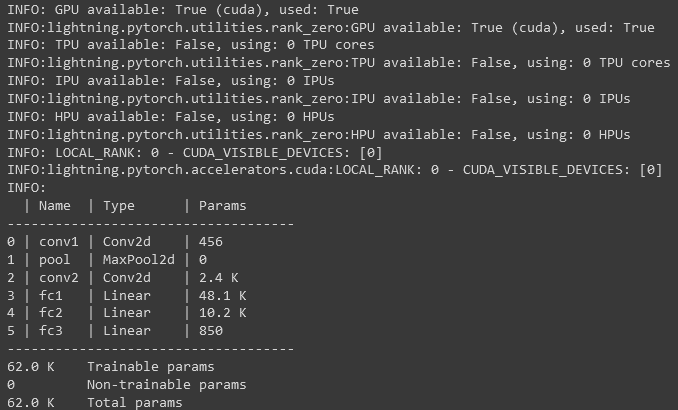
You can checkout the full code in my github repository.